Piloting a GenAI Chatbot for Students

TL;DR
I led research, piloting, and evaluation for a GenAI chatbot designed to help students apply for financial aid. Post-release, I partnered with a data analyst to develop a robust AI quality model that drove continuous improvements in each product sprint. These improvements resulted in an increase in the bot response accuracy from 71% to 85% in three months.
Research type: Evaluative Research
UX skills: Feedback Survey, Behavioral Observations, Human Evaluation of AI Chat Content
My role: UX Research and Evaluation Lead
Cross-functional team: UI Design, Graphic Design, Data Analytics, Product Management, Engineering
Timeline: 1 month to build, continuous monitoring for evaluation
Context
When the US government announced a new version of the Free Application for Federal Student Aid (FAFSA) in 2023, we kicked off a project to overhaul our SMS-based FAFSA support bot, Wyatt. I led usability research with students using the new FAFSA prototype, and uncovered a need for a new product: a web-based chatbot. Using my research insights, our team built and released a beta web product using GenAI in just one month, in time for the 2024 financial aid deadline.


Wyatt answers any questions students may have as they’re filling out the FAFSA. Students access the bot through the home page and can either sign up for texting or start chatting with Wyatt right away.
Post-release, I led user feedback collection, as well as manual analysis of users’ conversations with the bot. This case study outlines this post-launch, evaluative stage of Wyatt.
Process
GOAL
Evaluate overall bot performance, including:
- Measuring user satisfaction with the bot
- Understanding how users are using the bot
- Evaluating chatbot response accuracy
METHODS
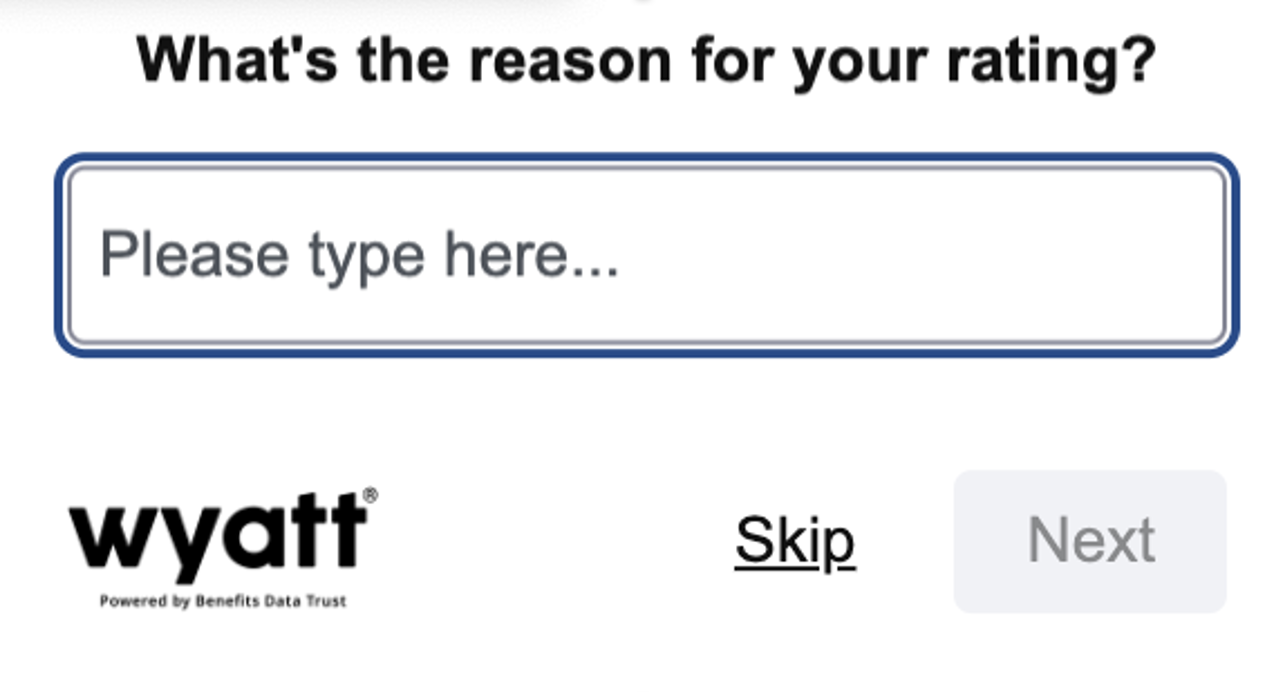
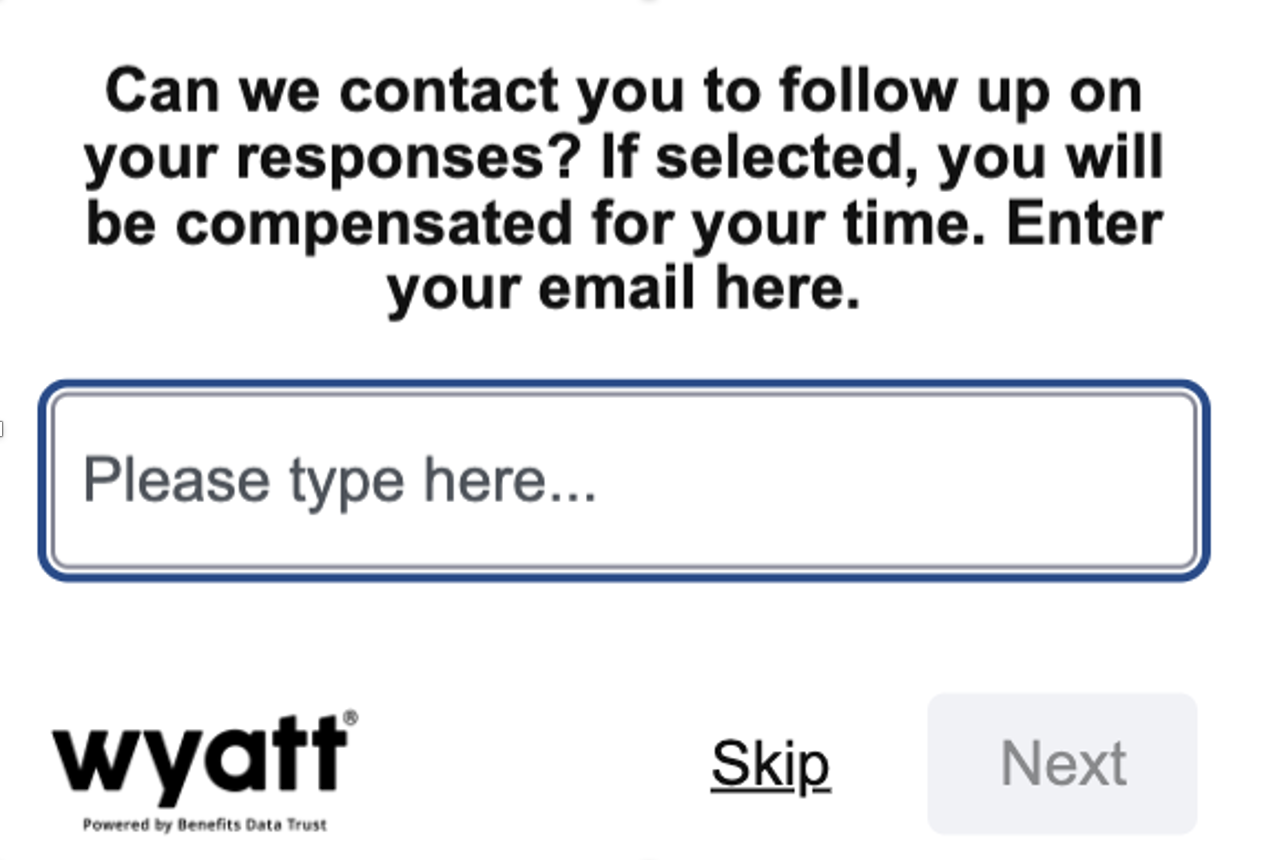
1. Hotjar feedback Widget Questions (Bot Landing Page) & Recording Observations

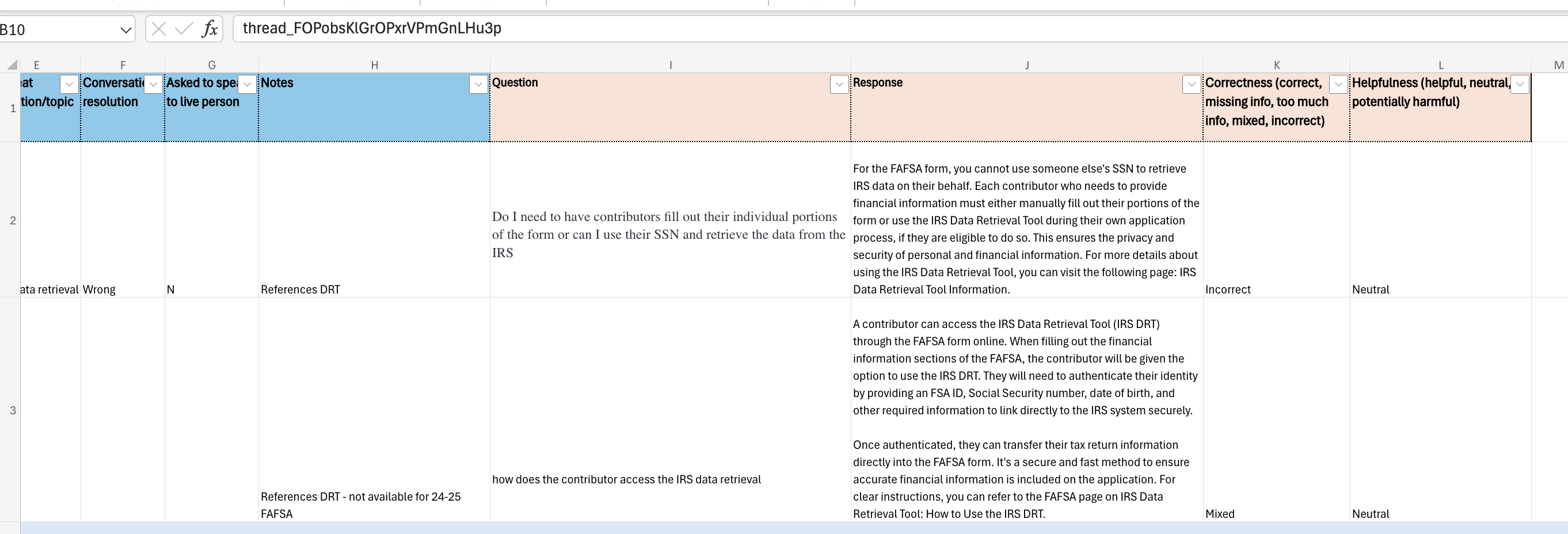
2. Manual Conversation Analysis of Chat Prompt/Response Pairs
Our team evaluated a sample of the chat conversations every week, both at the sentence level (prompt/response pairs), and at the conversation level (conversation in context). Prior to the release of the GenAI bot, we rated Wyatt’s responses simply as correct and incorrect. But once we implemented GenAI technology, we realized we needed more nuance as the generated responses didn’t perfectly match our vetted answer data set.
Over time, we evolved the quality model to rate each Q&A pair on a continuum of “correctness”. We also started rating on a second dimension, “helpfulness,” paying particular attention to flagging and fixing any potentially harmful answers.

For the conversations in context, we started out by noting how often the user had to repeat or rephrase a question before the bot understood. We also looked at conversation resolution, as in, did the final exchange provide a correct answer to the user? And we noted whenever someone wanted to speak to a live agent, as well as rating the conversation sentiment as positive or negative based on any frustration or delight that the user expressed.
We quickly abandoned the sentiment rating as we found it wasn’t useful – most users tend to be neutral in the conversations with Wyatt and presumably just leave the chat if they are frustrated with the answers they’re getting.

Analysis & Synthesis
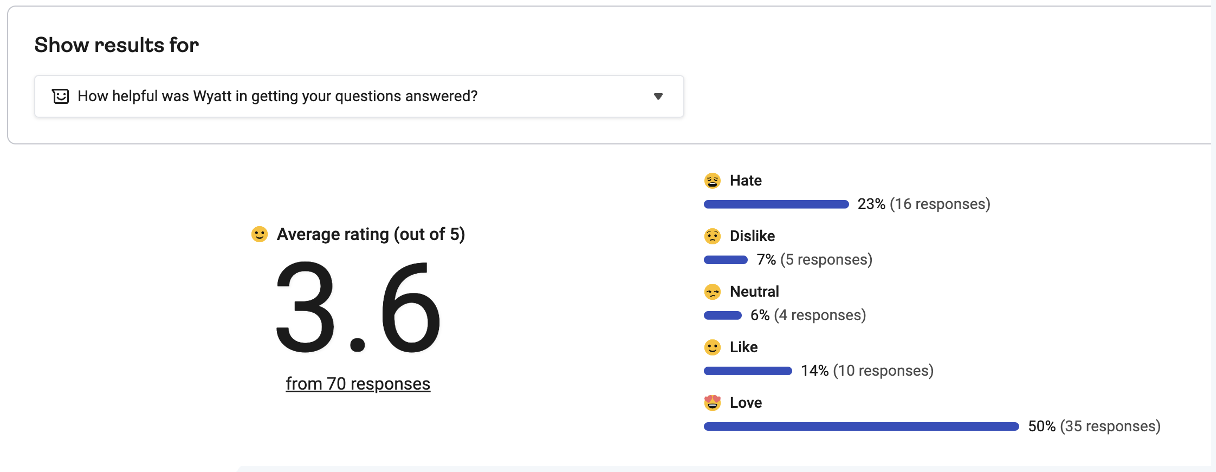
Through the Hotjar feedback questions, I got weekly quantitative insight into user satisfaction based on the average rating for the first question (how helpful was Wyatt in getting your questions answered). I then drilled into the low ratings to see if I could figure out why the user was unhappy – by looking at the reason for the rating (question 2) alongside a recording of the session.
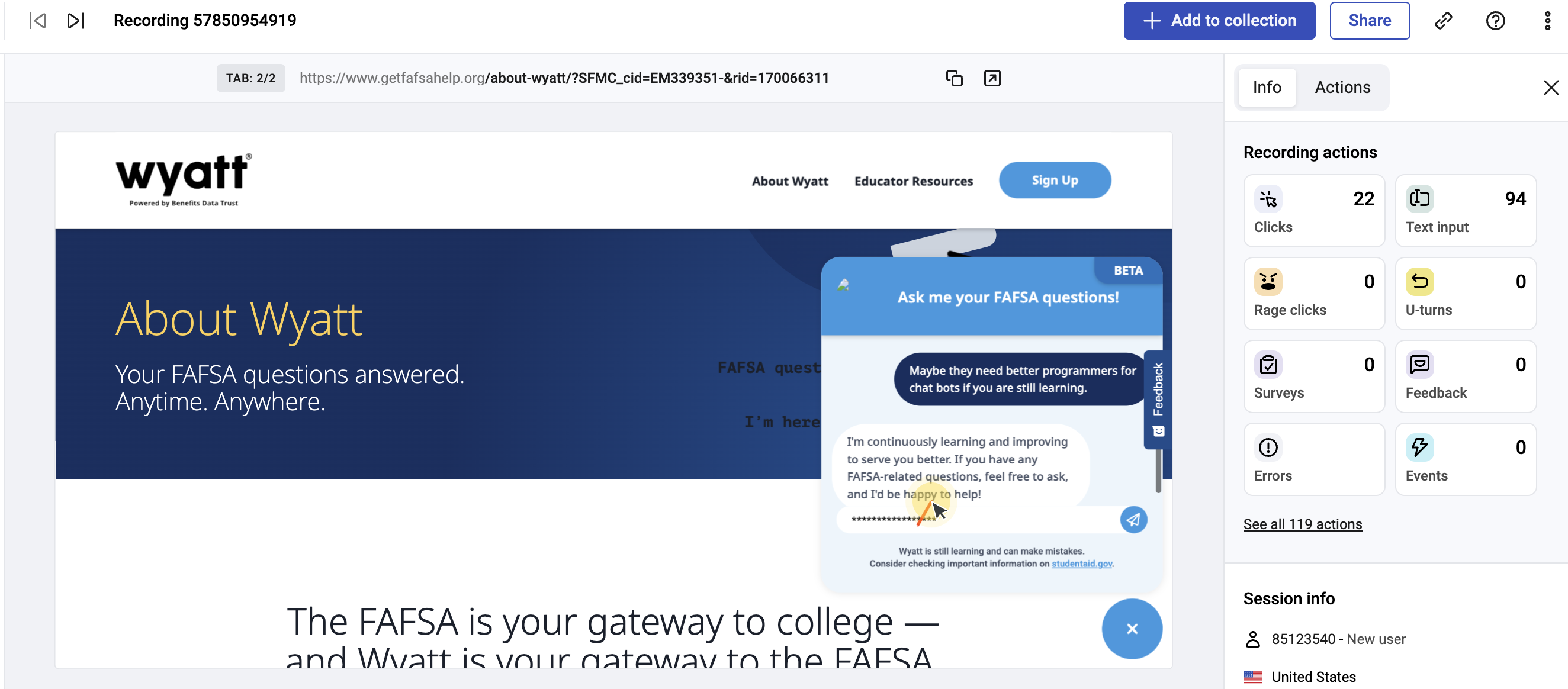
For the manual analysis, we downloaded a sample of conversations into a spreadsheet to evaluate each sentence pair and conversation in context.
Outputs
WEEKLY REPORT
Every week, I collaborated with Wyatt’s product manager and the data analytics team on an internal report about the bot’s performance metrics, to keep stakeholders in the loop.

JIRA TICKETS
Using both the user feedback (from the feedback survey and through watching recordings) and the manual chat content evaluation, I logged bot fix tickets in Jira for each sprint. These were reviewed and assigned to the relevant team members during sprint planning.
Impact
The average user satisfaction score increased from 3.3 (on a 5-point scale) to 4.2 in three months of continued improvements to the bot content and UX/UI enhancements.
Wyatt’s response accuracy increased from 71% to 85% in that same three-month period, through improvements to bot content.

Reflections
Human evaluation of chat bot content, though crucial to understanding nuances in GenAI conversations, is extremely time-consuming. Budget restrictions meant we had a very small team doing this manual work, as well as not having the resources to implement automated evaluation of the content to supplement the human evaluation. In an ideal world, we would have more people doing the manual evaluation alongside an automated evaluation process.
I was also planning on doing more direct research and testing with users of the web bot, such as usability testing post-launch and contextual inquiry with users using the bot to complete the FAFSA in real-time. Unfortunately, before I was able to implement this, the nonprofit running Wyatt ceased operations.
